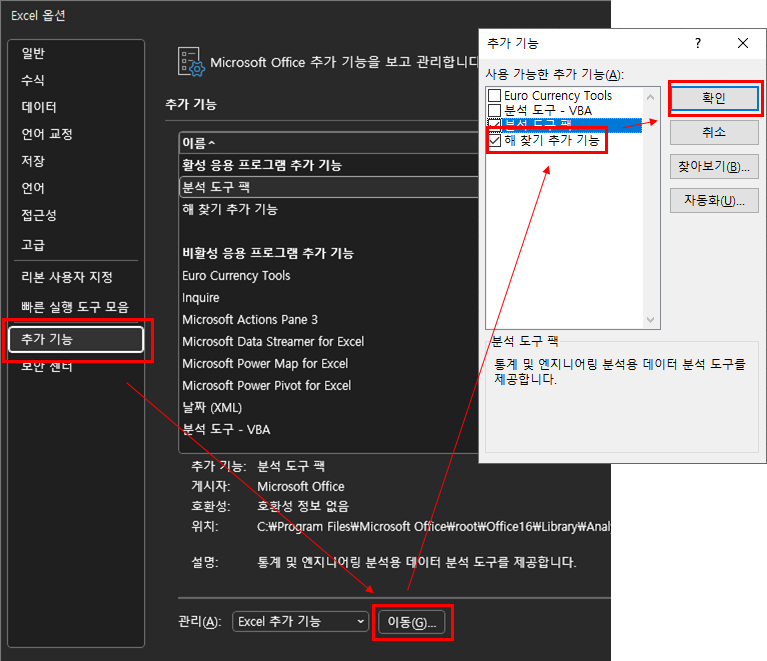
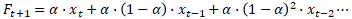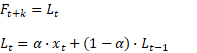즉 생긴거는 문자이지만 숫자일 수도 있고, 숫자 10이 "10권"으로 표시될 수도 있다는 뜻입니다.
특히 통계 프로그램을 통해 생성된 숫자나 외부파일을 복사해서 붙이는 경우 문자로 많이 붙여넣어집니다.
이런경우에 문자를 숫자로 고쳐주는 NUMBERVALUE 함수에 대해서 알아보겠습니다.
NUMBERVALUE(text, [decimal_separator], [group_separator]) :텍스트를 원하는 형식에 숫자로 변환합니다.
text : 숫자로 표시될 문자입니다. 함수가 숫자로 해석할 수 없는 경우 #VALUE! 에러를 반환합니다.
[decimal_separator] : 소숫점을 확인합니다. text안에서 decimal_separator를 찾아서 똑같은게 있다면 그 오른쪽에 있는 숫자는 소수점 이하로 표시합니다. 같은 decimal_separator가 2개 이상이면 오류(#VALUE!)가 발생합니다.
[group_separator] : 구분표시입니다. text안에서 group_separator 를 찾아서 똑같은게 있다면 무시합니다.
빈칸은 자동으로 무시합니다. 3 0 0 0은 3000으로 자동으로 변환됩니다.
인수에 대한 설명이 어렵습니다.
하지만 동작이 쉬운 함수로 예를 들어서 보면 명확합니다.
=NUMBERVALUE("1서43장55","장","서") 라고 하면 결과는 "143.55"가 됩니다.
"서"는 뭔가 구분기호로 생각해서 없애버리고 "장"은 소수점으로 빼버린 겁니다.
예시
문자로 표기되어 있고 중간에 공백이 있어서 연산이 안되는 왼쪽에 비해,
NUMBERVALUE로 변환한 식은 계산이 바로됩니다.
요즘은 사실 엑셀에서 어지간한 텍스트 형식의 숫자는 연산이 바로 지원되게 만들어져 있습니다.
텍스트 형식으로 '34 + '55을 하면 그냥 89라고 결과가 뜹니다.
스마트하게 만들어지는 추세죠.
언제가 NUMBERVALUE 함수는 장기적으로 없어지는 과거의 유물이 될 수도 있겠네요.
하지만 숫자가 텍스트가 되어서 문제가 생기는 경우는 언제든지 있습니다.
오른쪽 관중수가 텍스트입니다.
텍스트로 표시된 숫자는 거의 대부분 칸의 왼쪽 위에 초록색 삼각형이 있어 알 수 있습니다.
하지만 이것도 예외는 언제든지 있어서 혼돈될 때가 있습니다.
외부 프로그램으로 CSV 파일을 만들거나, 혹은 복사해서 붙일 때는 텍스트로 적용되었는지 아닌지를 확인할 필요가 있습니다.
지수평활법 : 수준(Level), 추세(Trend), 계절성(Seasonality)로 미래정보를 예상
ETS 모델 : 지수평활법에 Error를 추가하여 불확실성을 최소화
같은 방법이 있습니다.
엑셀에서는 FORECAST.ETS 함수로 이 ETS 예측 솔루션을 제공합니다.
그래도 미래예측이 다 그렇지만, 많은 불확실성을 가지고 있습니다.
불확실성을 계산하는 파생 함수인 CONFINT 함수를 알아보겠습니다.
1. FORECAST.ETS.CONFINT 함수
FORECAST.ETS.CONFINT(target_date, values, timeline, [confidence_level], [seasonality], [data_completion], [aggregation]) :ETS 함수로 계산한 날짜의 예측한 값에 대한 신뢰구간을 반환합니다. 예측된 결과 95%에 반경에 속할 것이라는 것을 계산할 수 있습니다. 반대로 말하면 이 반경이 좁을 수록 ETS로 예상한 값이 정확도가 높다고 할 수 있습니다.
target_date : 예측하려는 시점의 숫자입니다. 날짜 혹은 시간, 숫자일 수 있습니다. 원본데이터의 시간인 timeline에서 몇 단계 멀어져 있는지 계산해서 수행합니다. 이 시간이 timeline 안쪽인 경우에는 #NUM!의 에러를 출력합니다.
values : 측정한 과거의 값들입니다. 범위로 입력해야하고 정확하고 많은 데이터가 필요합니다.
timeline : 측정한 값들의 시간 데이터입니다. 일정한 간격의 값으로 구성되어야 하지만 꼭 정렬될 필요는 없습니다. 함수가 자동으로 시간순으로 정렬하며 줍니다. 여기에 계산이 불가능한 텍스트등이 포함되면 #NUM을 출력됩니다. values와 같은 개수여야 합니다.
[confidence_level] : 구간의 신뢰도 수준을 나타내는 값으로 0 ~ 1 사이의 숫자입니다. 입력하지 않는 기본값은 0.95입니다.
[seasonality] : 계절성을 입력하는 항목으로 선택 요소입니다. 1은 기본값으로 엑셀 함수가 자동으로 계절성을 계산하게 합니다. 0은 계절성이 없는 모델을 사용하여 계산하는 선형모델을 사용합니다. 양의 정수를 입력하면 사용자가 입력한 seasonality를 사용해서 계산합니다. 그 외의 모든 값에 #NUM 오류가 반환됩니다. 지원되는 최대 seasonality는 8,760(1년 동안의 시간)입니다. 해당 숫자보다 seasonality가 높으면 #NUM! 오류가 반환됩니다.
[data_completion] : 계측된 데이터에 빈값을 어떻게 할지 결정하는 선택요소입니다. 이 함수에서는 최대 30%의 누락지점을 매꾸는 알고리즘이 지원됩니다. 1 : 기본값으로 가까운 지점의 평균을 사용해서 누락된 DATA를 계산합니다. 0 : 누락된 지점을 0으로 간주하는 알고리즘입니다.
[aggregation] : timelie 요소간에 일정한 단계가 필요한데 중복되는 타임 스탬프가 있을 수 있습니다. aggregation은 이 값들을 어떻게 처리할지 결정합니다. 1 : 기본값으로 그 값들을 AVERAGE를 계산합니다. 2 : SUM으로 계산합니다. 3 : Count로 계산합니다. 4 : CountA로 계산합니다. 5 : 최소값(Min)으로 계산합니다. 6 : 최대값(Max)으로 계산합니다. 7 : 중위값(Median)으로 계산합니다.
2. 함수 사용 예시
함수는 범위를 반환하기 때문에 ETS로 구한값을 더하거나 빼면 됩니다.
EST ± CONFINT를 적용하면 해당 신뢰구간을 구할 수 있습니다.
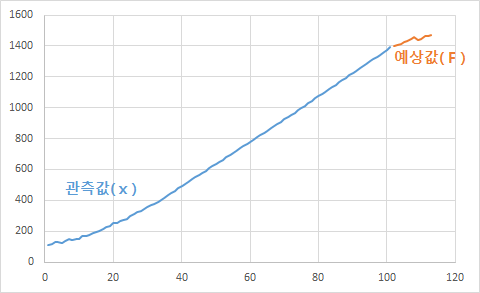
과거 실측기온을 대상으로 ETS를 이용해서 내년 기온을 예상해 봤습니다.
기온을 가지고 ETS
일단 보이지는 않지만 1960년부터 지금까지 서울의 월평균 기온을 구한것입니다.
예상값 선에서 CONFINT로 구한 값이 위아래로 범위를 만들고 있습니다.
95% 신뢰구간임에도 이 범위는 ± 3 ℃ 가까운 굉장히 큰 것으로 기후 예상이 어렵다는 것을 알 수 있습니다.
기온값과 예상값
내년에 진짜 이대로 가는지 보는 것도 좋을 것 같습니다.
ETS함수로 먼미래까지도 계산할 수 있습니다.
예상하는 미래를 좀더 멀리해서 2030년까지 보겠습니다.
시간에 따른 오차가 점점 커지는 것을 볼 수 있습니다.
먼 미래가 예상하기 힘든 점이 반영되는 것입니다.
좀더 먼 예상
그리고 아주 약간이지만 중심치가 +로 가는 것이 있습니다.
그건 아무래도 지구 온도가 올라가는 것이 반영된 것 같습니다.
ETS 계산법은 기온을 예상하기 위한 수많은 데이터가 없이 통계적으로도 어느정도 예상할 수 있는 장점이 있습니다.
target_date : 예측하려는 시점의 숫자입니다. 날짜 혹은 시간, 숫자일 수 있습니다. 원본데이터의 시간인 timeline에서 몇 단계 멀어져 있는지 계산해서 수행합니다. 이 시간이 timeline 안쪽인 경우에는 #NUM!의 에러를 출력합니다.
values : 측정한 과거의 값들입니다. 범위로 입력해야하고 정확하고 많은 데이터가 필요합니다.
timeline : 측정한 값들의 시간 데이터입니다. 일정한 간격의 값으로 구성되어야 하지만 꼭 정렬될 필요는 없습니다. 함수가 자동으로 시간순으로 정렬하며 줍니다. 여기에 계산이 불가능한 텍스트등이 포함되면 #NUM을 출력됩니다. values와 같은 개수여야 합니다.
[seasonality] : 계절성을 입력하는 항목으로 선택 요소입니다. 1은 기본값으로 엑셀 함수가 자동으로 계절성을 계산하게 합니다. 0은 계절성이 없는 모델을 사용하여 계산하는 선형모델을 사용합니다. 양의 정수를 입력하면 사용자가 입력한 seasonality를 사용해서 계산합니다. 그 외의 모든 값에 #NUM 오류가 반환됩니다. 지원되는 최대 seasonality는 8,760(1년 동안의 시간)입니다. 해당 숫자보다 seasonality가 높으면 #NUM! 오류가 반환됩니다.
[data_completion] : 계측된 데이터에 빈값을 어떻게 할지 결정하는 선택요소입니다. 이 함수에서는 최대 30%의 누락지점을 매꾸는 알고리즘이 지원됩니다. 1 : 기본값으로 가까운 지점의 평균을 사용해서 누락된 DATA를 계산합니다. 0 : 누락된 지점을 0으로 간주하는 알고리즘입니다.
[aggregation] : timelie 요소간에 일정한 단계가 필요한데 중복되는 타임 스탬프가 있을 수 있습니다. aggregation은 이 값들을 어떻게 처리할지 결정합니다. 1 : 기본값으로 그 값들을 AVERAGE를 계산합니다. 2 : SUM으로 계산합니다. 3 : Count로 계산합니다. 4 : CountA로 계산합니다. 5 : 최소값(Min)으로 계산합니다. 6 : 최대값(Max)으로 계산합니다. 7 : 중위값(Median)으로 계산합니다.
2. FORECAST.ETS.SEASONALITY 함수
FORECAST.ETS.SEASONALITY(values, timeline, [data_completion], [aggregation]) :관측된 데이터가 일정간격으로 패턴이 반복되는 것을 계절성(Seasonality)라고 합니다.
ETS에서 사용하는 계절성의 주기를 계산해주는 함수입니다.
ETS 함수에서 계절성을 자동으로 구해서 계산하기는 하지만 따로 뽑아서 확인할 필요가 있습니다.
미래 예측 분야에서는 감각적으로 사람이 한번 확인하는 것이 아직 중요합니다.
values : 계절성을 파악하려는 데이터의 값들입니다. timeline에 대응하는 값들의 범위 입니다.
timeline : 값이 배열된 시간의 데이터입니다. 시간들 사이에는 일정한 간격이 필요합니다. 범위의 데이터들이 꼭 순차적으로 정렬될 필요없이 함수가 알아서 정렬을 합니다. 0을 입력하면 #NUM! 오류를 출력하고 문자를 입력하면 해당 데이터는 무시하고 계산합니다.
[data_completion] : 계측된 데이터에 빈값을 어떻게 할지 결정하는 선택요소입니다. 이 함수에서는 최대 30%의 누락지점을 매꾸는 알고리즘이 지원됩니다. 1 : 기본값으로 가까운 지점의 평균을 사용해서 누락된 DATA를 계산합니다. 0 : 누락된 지점을 0으로 간주하는 알고리즘입니다.
[aggregation] : timelie 요소간에 일정한 단계가 필요한데 중복되는 타임 스탬프가 있을 수 있습니다. aggregation은 이 값들을 어떻게 처리할지 결정합니다. 1 : 기본값으로 그 값들을 AVERAGE를 계산합니다. 2 : SUM으로 계산합니다. 3 : Count로 계산합니다. 4 : CountA로 계산합니다. 5 : 최소값(Min)으로 계산합니다. 6 : 최대값(Max)으로 계산합니다. 7 : 중위값(Median)으로 계산합니다.
3. FORECAST.ETS.STAT 함수
FORECAST.ETS.STAT(values, timeline, statistic_type, [seasonality], [data_completion], [aggregation]) :ETS 모델을 계산할 때는 몇가지 계수를 계산해야 합니다. FORECAST.ETS 함수는 그것을 자동을 계산해서 결과에 반영합니다.
.STAT 함수의 경우 그 값들을 사용자가 볼 수 있게 하나하나 출력하는 함수입니다.
values : ETS 모델에 적용할 DATA들이고 timeline에 대응되는 값들입니다.
timeline : 값이 배열된 시간의 데이터입니다. 시간들 사이에는 일정한 간격이 필요합니다. 범위의 데이터들이 꼭 순차적으로 정렬될 필요없이 함수가 알아서 정렬을 합니다. 0을 입력하면 #NUM! 오류를 출력하고 문자를 입력하면 해당 데이터는 무시하고 계산합니다.
Statistic_type : 함수에서 반환할 값들을 구합니다. 필수요소임으로 꼭 사용자가 선택하여 입력하여야 합니다. 1 : EST 알고리즘의 α 값으로 수준(Level)의 매개 변수입니다. 2 : EST 알고리즘의 β 값으로 추세(Trend)의 매개 변수입니다. 3 : EST 알고리즘의 γ 값으로 계절성(Seasonality)의 매개 변수입니다. 4 : MASE 메트릭 값입니다. 예측정확도의 측정값이 절대 배율 오차메트릭을 반환합니다. 5: SMAPE 메트릭 값입니다. 백분율 오류를 기반으로 하는 SMAPE 측정값을 반환합니다. 6 : MAE 메트릭 값입니다. 백분률 오류를 기반으로 하는 MAE 측정값을 반환합니다. 7 : RMSE 메트릭 값입니다. 백분률 오류를 기반으로 하는 RMSE 측정값을 반환합니다. 8 : 기록된 timeline의 단계 크기를 반환합니다.
[seasonality] : 계절성을 입력하는 항목으로 선택 요소입니다. 1은 기본값으로 엑셀 함수가 자동으로 계절성을 계산하게 합니다. 0은 계절성이 없는 모델을 사용하여 계산하는 선형모델을 사용합니다. 양의 정수를 입력하면 사용자가 입력한 seasonality를 사용해서 계산합니다. 그 외의 모든 값에 #NUM 오류가 반환됩니다. 지원되는 최대 seasonality는 8,760(1년 동안의 시간)입니다. 해당 숫자보다 seasonality가 높으면 #NUM! 오류가 반환됩니다.
[data_completion] : 계측된 데이터에 빈값을 어떻게 할지 결정하는 선택요소입니다. 이 함수에서는 최대 30%의 누락지점을 매꾸는 알고리즘이 지원됩니다. 1 : 기본값으로 가까운 지점의 평균을 사용해서 누락된 DATA를 계산합니다. 0 : 누락된 지점을 0으로 간주하는 알고리즘입니다.
[aggregation] : timelie 요소간에 일정한 단계가 필요한데 중복되는 타임 스탬프가 있을 수 있습니다. aggregation은 이 값들을 어떻게 처리할지 결정합니다. 1 : 기본값으로 그 값들을 AVERAGE를 계산합니다. 2 : SUM으로 계산합니다. 3 : Count로 계산합니다. 4 : CountA로 계산합니다. 5 : 최소값(Min)으로 계산합니다. 6 : 최대값(Max)으로 계산합니다. 7 : 중위값(Median)으로 계산합니다.
4. 함수 적용해 보기
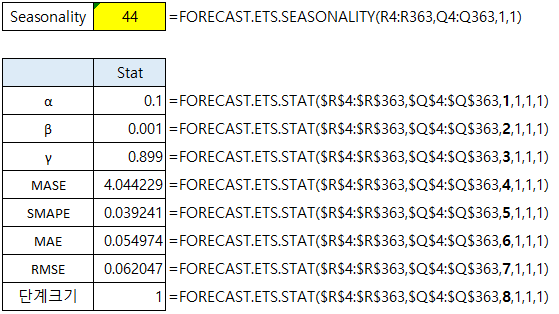
제가 임의로 만들어서 ETS 함수를 적용해 보겠습니다.
임의로 만든 숫자는 sin 함수에 8을 곱해서 45개를 주기로 하는 계절성을 만들었고,
exp로 감쇄하는 추세를 만들었습니다.
아래 결과를 보면 계절성의 주기는 44개로 계산했고 예상값의 경우 거의 일치하는 모양입니다.