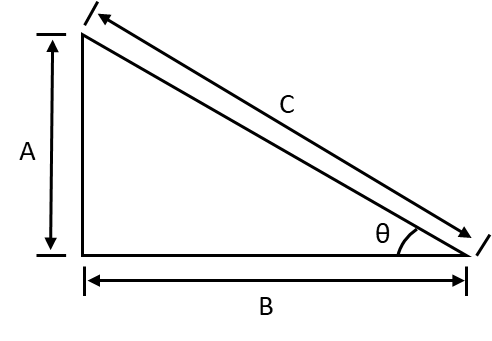
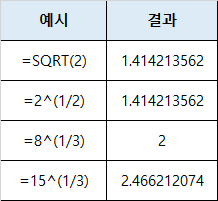
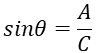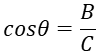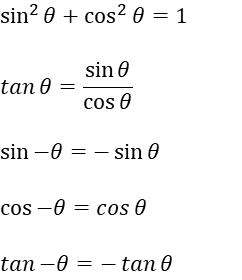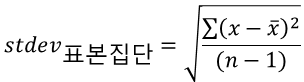삼각함수의 사용하는 예에 대해서 소개하려고합니다.
기하학에서는 아주 오래 전 부터 삼각 측량법(Triangulation Surveying)으로 위치를 파악해 왔습니다.
오래되었고 기본적이지만 조건만 맞으면 아주 정확합니다.
1. 삼각 측량법 사용
A와 B를 정확하게 알고 있을 때 관측된 C의 위치를 계산합니다.
A와 B에서 관측하여 각도 ∠CAB(α)와 ∠ABC( β )를 측정합니다.

삼각형 △ABC는 보통은 직각삼각형이 아닙니다.
그래서 직사각형을 만드는 D를 먼저 만들어 알아내야 합니다.
먼저 삼각형의 내각의 합은 180˚가 되니 ∠ACB( γ )를 구할 수 있습니다.
그럼 사인법칙이 사용할 수 있습니다.
사인 법칙을 활용해서 거리를 AC의 거리를 알아냈습니다.
이제 AD를 알아내겠습니다.
이제 AC와 AD를 다 구했습니다.
피타코라스 법칙으로 DC를 구하면 C의 위치를 구한 것입니다.
2. 산의 높이 구하기
이번에는 산의 높이를 측정한다고 치겠습니다.
먼저 산 아래에서 정확한 두점의 위치를 찍습니다.
그리고 산꼭대기를 보면 기울어진 삼각형을 만들수가 있죠.
① 직각이 되는위의 방법과 같이 위치 D를 만들고 CD의 길이를 구합니다.
② D로 이동하여 다시 C까지의 각도 "??"를 측정합니다.(관측을 2번)
그럼 CD의 길이와 각도 ??를 알고 있습니다.
산의 높이(CE) = CD * sin ?? 가 됩니다.
3. 삼각측량법의 응용
위의 원리를 이용해서 여러 개의 중개탑을 설치해서 여러 위치를 관측합니다.
그럼 이 데이터들로 연결해서 많은 삼각형을 만들수 있습니다.
이걸 이용해서 이 안의 거리를 구하는 방식으로 어디든 위치를 알 수 있습니다.
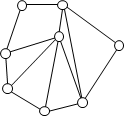
그래도 측량에는 사실 오차가 조금 있습니다.
이 때 한개의 위치를 여러개의 신호탑에서 삼각 계측법을 사용해서 위치의 정밀도를 높입니다.
복잡한 망을 만들어 위치를 정밀하게 파악하는 네비게이션도 사실 근본적으로는 삼각 계측법을 다중으로 전개합니다.
지구가 둥글기 때문에 넓은 거리를 이동할 때는 보완하는 계산이 따로 필요하기는 합니다.
기술이 발달함에 따라 초단위의 각도변화도 계산할 수 있어 별의 거리도 측정하고는 합니다.
단순하지만 강력한 거리 파악법인 삼각 측량법은 현대에서도 널리 쓰이고 있습니다.
아직도 추가적인 활용법이 연구되고 있다고 하니 간단한 아이디어가 얼마나 힘이 있는지 알 수 있습니다.
'수학 이야기' 카테고리의 다른 글
| 최소공배수는 무엇이며 어떻게 구하거나 계산하는지 알아봅시다.(Least Common Multiple, LCM) (0) | 2023.07.10 |
|---|---|
| 약수와 공약수 배수와 공배수의 개념과 실제로 어떤 경우에 적용되는지 알아봅시다 (0) | 2023.07.09 |
| 기하학의 기본 도구인 삼각비와 삼각함수 의미와 뜻 그리고 기본적인 공식에 대해서 (0) | 2023.06.08 |
| 각도를 나타내는 단위 도, 분, 초와 라디안의 뜻과 엑셀로 계산하기(radian 함수와 degree 함수) (0) | 2023.06.08 |
| 제곱과 제곱근의 의미와 대각선 길이를 피타고라스 법칙으로 계산하고 엑셀(EXCEL)에서 값 구하기(SQRT 함수) (0) | 2023.06.07 |